RabbitMQ stores contents of a queue on a single node by default. We can optionally mirror these contents across different nodes.
Each mirrored queue has one master and one or more mirrors. Any operation that takes place on the queue like adding a message, consuming a message etc. happens on the master node first. Since all the messages are replicated across all mirrors and all the operations are also propagated to them, adding mirrors does not reduce the load on the queue. However, it provides us with high availability. In case, the node on which master for your mirror is located goes down, one of the mirrors can take over without impacting the availability of the queue.
We can setup various different mirroring policies to suit our availability requirements. RabbitMQ provides 3 policies out of the box:
- Exactly: Using this you can specify exact number of replicas(master + mirrors) for the queue in the cluster.
- All: Queue will be replicated across all nodes on cluster. Use this option carefully as this might put too much network I/O, disk space usage etc. on your cluster due to update propagation across all N nodes.
- Nodes: Queue is mirrored to nodes listed in the node names parameter.
For a 3 or 5 nodes cluster you should set the replication policy to replicate to majority of nodes, i.e. 2 and 3 respectively.
To equally distribute load among different nodes on your cluster, your queue masters should be equally distributed among all nodes. you should change your queue_master_locator key in the configuration to one of the following values:
- Pick the node hosting the minimum number of bound masters: min-masters
- Pick the node the client that declares the queue is connected to: client-local
- Pick a random node: random
Additionally, you can also specify the master location for a specific queue using x-queue-master-locator queue declare argument.
Even after setting up these policies, you might still end up with unbalanced load across your cluster due to node restarts. In this case, you can migrate masters for some of the queues on a heavily loaded node to a less loaded one. To do this, you can setup a policy with higher precedence then the current mirroring policy using RabbitMQ admin dashboard. For a queue named user-updates, we can define the policy like this:
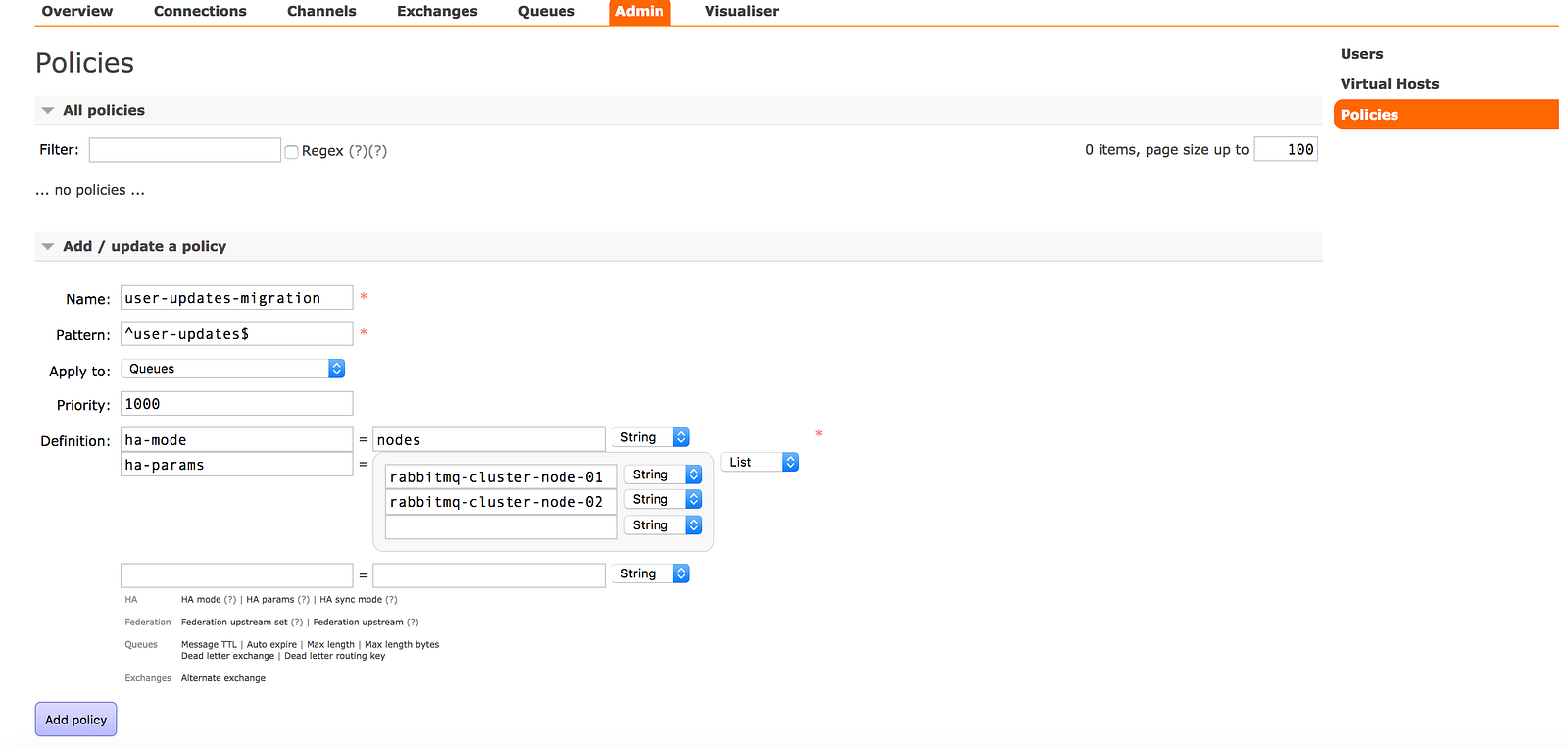
Once you click on add policy, user-updates queue would be migrated to node-01 and node-02 from its current location. However, you have to be careful while doing this. Since, changing the HA policy might cause the master to go away all together if its not listed in new policy, RabbitMQ keeps the existing master node, till at least one of the mirrors has synchronized.
For example, if a queue is on [A B] (with A the master), and you give it a nodes policy telling it to be on [C D], it will initially end up on [A C D]. As soon as the queue synchronizes on its new mirrors [C D], the master on A will shut down.
Comments
Post a Comment